Chatbot AI modern tidak lagi sekadar mengandalkan training data statis. RAG (Retrieval Augmented Generation) adalah teknik yang memungkinkan chatbot kamu untuk mengambil informasi real-time dari knowledge base, sehingga respons lebih akurat, terkini, dan relevan dengan konteks pengguna.
Bayangkan kamu punya chatbot customer support. Tanpa RAG, model hanya bisa merespons berdasarkan data training lama. Dengan RAG, chatbot bisa langsung mencari dokumen help center, FAQ, atau update produk terbaru saat menjawab pertanyaan pelanggan. Itu bedanya antara chatbot biasa dan chatbot yang benar-benar berguna.
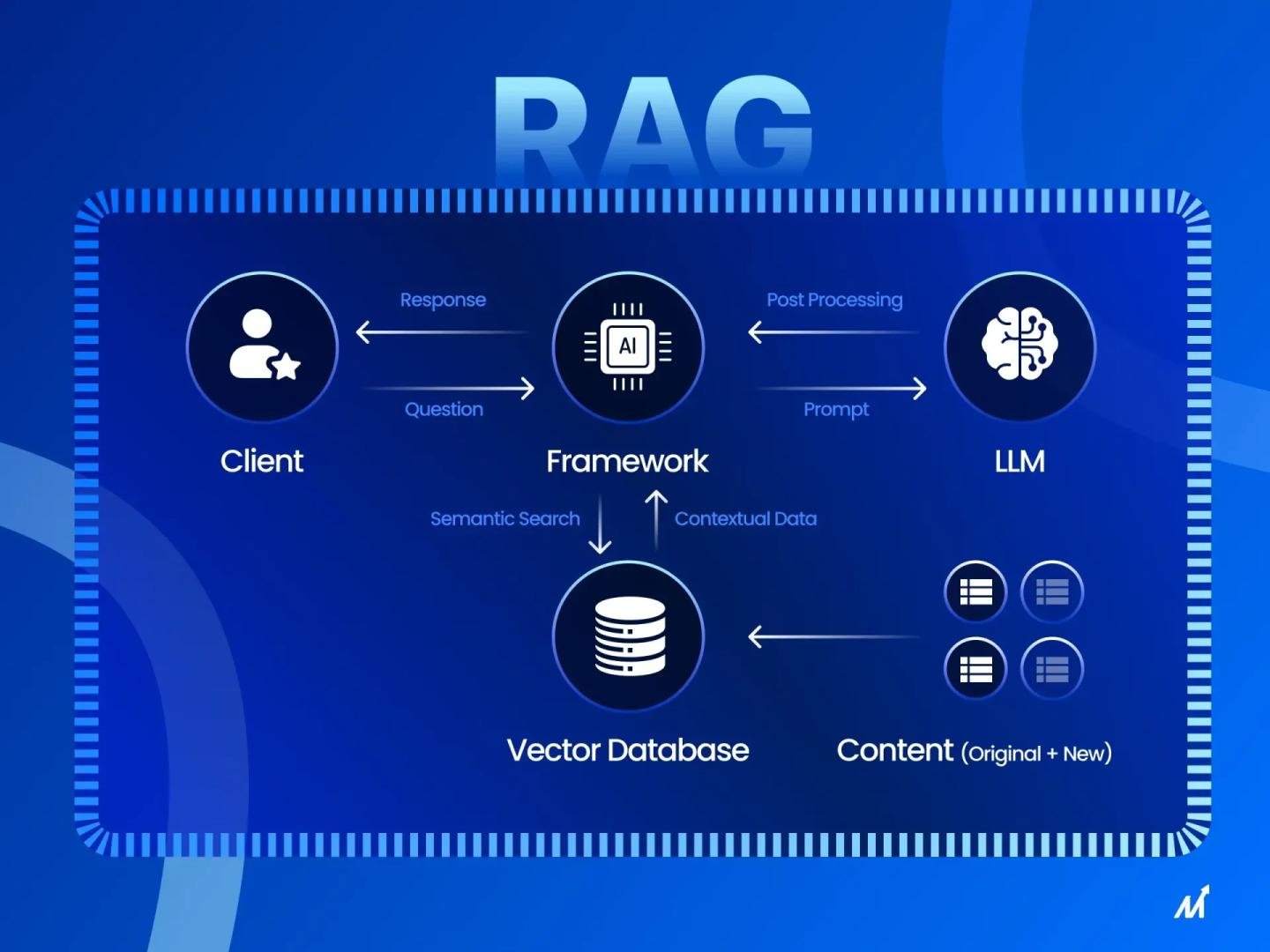
Apa itu RAG dan Bagaimana Cara Kerjanya?
RAG adalah singkatan dari Retrieval Augmented Generation. Secara sederhana, RAG bekerja dalam dua tahap:
- Retrieval (Pengambilan): Sistem mencari dokumen atau informasi relevan dari knowledge base berdasarkan pertanyaan pengguna.
- Generation (Generasi): Model bahasa (LLM) menggunakan dokumen yang diambil tadi sebagai konteks untuk menghasilkan respons yang lebih akurat.
Tanpa RAG, LLM hanya bergantung pada pengetahuan yang sudah dilatih. Dengan RAG, LLM bisa mengakses informasi eksternal secara real-time. Ini sangat berguna untuk domain spesifik seperti dokumentasi teknis, kebijakan perusahaan, atau data yang sering berubah.
Alur kerja RAG secara umum adalah: Pengguna mengirim query → Query diubah menjadi embedding vektor → Sistem mencari dokumen serupa di vector database → Dokumen relevan digabung dengan query asli → LLM menghasilkan respons berdasarkan konteks lengkap.
Komponen Utama RAG: Vector Database dan Embedding
Inti dari RAG adalah vector database. Ini adalah basis data yang menyimpan representasi vektor dari dokumen atau teks kamu. Saat pengguna bertanya, query tersebut diubah menjadi vektor dengan model embedding yang sama, kemudian sistem mencari vektor dokumen yang paling mirip.
Beberapa vector database populer yang bisa kamu gunakan:
- Pinecone: Managed vector database, mudah diintegrasikan, cocok untuk startup dan project kecil-menengah.
- Weaviate: Open-source, flexible, bisa di-host sendiri atau cloud.
- Milvus: Open-source, performa tinggi, scalable untuk data besar.
- Qdrant: Modern, ringan, support untuk production use case.
- Elasticsearch dengan vector search: Jika kamu sudah pake Elasticsearch, bisa langsung leverage fitur vector search-nya.
Untuk embedding (mengubah teks menjadi vektor), kamu bisa pakai model open-source seperti sentence-transformers, atau API berbayar seperti OpenAI embeddings. Pilihan tergantung kebutuhan latency, akurasi, dan budget kamu.
Langkah-Langkah Implementasi RAG untuk Chatbot
Berikut adalah alur implementasi RAG dari awal hingga production:
1. Persiapkan Knowledge Base
Kumpulkan dokumen yang akan menjadi source informasi chatbot kamu. Bisa berupa file PDF, artikel blog, dokumentasi API, FAQ, atau database SQL. Pastikan dokumen terstruktur dengan baik dan dilengkapi metadata (judul, tanggal, kategori, dll).
2. Segmentasi dan Cleaning Dokumen
Dokumen panjang perlu dipotong menjadi chunk yang lebih kecil agar embedding lebih akurat. Contoh:
# Python pseudo-code untuk segmentasi dokumen
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = splitter.split_text(document)
for chunk in chunks:
print(chunk)Chunk size 500-1000 karakter biasanya cukup bagus. Overlap membantu menjaga konteks antar chunk agar tidak terputus.
3. Buat Embedding dan Indexing
Setelah segmentasi, ubah setiap chunk menjadi vektor dengan model embedding, lalu simpan ke vector database:
# Contoh dengan Pinecone dan OpenAI embeddings
import pinecone
from openai import OpenAI
client = OpenAI()
pinecone.init(api_key="YOUR_PINECONE_KEY")
index = pinecone.Index("chatbot-index")
for i, chunk in enumerate(chunks):
embedding = client.embeddings.create(
model="text-embedding-3-small",
input=chunk
).data[0].embedding
index.upsert([(f"chunk-{i}", embedding, {"text": chunk})])4. Implementasi Retrieval Function
Buat fungsi untuk mencari chunk relevan saat user bertanya:
def retrieve_relevant_docs(query, top_k=5):
query_embedding = client.embeddings.create(
model="text-embedding-3-small",
input=query
).data[0].embedding
results = index.query(query_embedding, top_k=top_k)
return [match["metadata"]["text"] for match in results["matches"]]5. Gabung Context dan Generate Response
Ambil dokumen retrieved tadi, gabung dengan query asli sebagai context, lalu minta LLM untuk generate respons:
def generate_rag_response(query):
relevant_docs = retrieve_relevant_docs(query)
context = "\n".join(relevant_docs)
messages = [
{"role": "system", "content": "Kamu adalah assistant yang helpful. Gunakan konteks berikut untuk menjawab."},
{"role": "user", "content": f"Konteks:\n{context}\n\nPertanyaan: {query}"}
]
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=messages
)
return response.choices[0].message.contentTips Meningkatkan Akurasi RAG Chatbot
- Quality over Quantity: Dokumen berkualitas tinggi lebih baik daripada banyak dokumen berkualitas rendah.
- Metadata yang Jelas: Tambahkan metadata setiap chunk (sumber, kategori, tanggal) untuk memudahkan filtering dan debugging.
- Re-ranking: Setelah retrieve top-k dokumen, gunakan model re-ranker untuk mengurutkan ulang berdasarkan relevansi.
- Query Expansion: Transform query pengguna menjadi beberapa variasi sebelum retrieve, untuk catch dokumen yang relevant dari angle berbeda.
- Monitor dan Feedback Loop: Kumpulkan data query yang gagal, improve knowledge base secara berkala.
- Hybrid Search: Kombinasi vector search (semantic) dengan keyword search (exact match) untuk hasil lebih robust.
Kesimpulan
RAG adalah game-changer untuk chatbot AI yang ingin memberikan respons akurat dan terkini. Dengan memahami konsep retrieval dan generation, serta menguasai vector database dan embedding, kamu sudah punya fondasi kuat untuk build chatbot production-ready.
Mulai dari skala kecil — siapkan knowledge base, pilih vector database yang cocok, implement retrieval function sederhana, dan iterate berdasarkan feedback pengguna. Seiring waktu, kamu bisa optimize dengan re-ranking, hybrid search, dan teknik advanced lainnya. Selamat mencoba!


